
OpenAIは、ユーザーの日常タスク解決を支援するためChatGPTをリリースしました。ChatGPTは意味のある出力を理解・生成する大規模言語モデル(LLM)です。このAIチャットボットのユーザーフレンドリーなインターフェースは、更新された機能性、高度な処理速度、応答精度を提供します。精密なタスク実行が可能なマルチモーダルモデル「GPT-4o」のリリース時にはブームが起きました。しかし2025年、GPT-5の登場は専門家、開発者、そして日常的なChatGPTユーザーの間で大きな話題となりました。本ブログではGPTフレームワークを深く掘り下げ、ChatGPTの異なるバージョンを探求し、GPTモデルを定義する主要な機能と考慮点を議論します。
GPTを理解する:モデルを支えるアーキテクチャ
GPT(Generative Pre-Trained Transformer)モデルアーキテクチャは、Transformerフレームワークに基づいています。これはVaswaniらが2017年の論文「Attention is All You Need」で初めて紹介したものです。これは自然言語処理(NLP)タスクのために特別に設計された深層学習アーキテクチャであり、GPT-3、GPT-4、GPT-5を含む現代の大規模言語モデルの基盤となっています。
中核アーキテクチャ:トランスフォーマーデコーダー
GPTは、元のトランスフォーマーアーキテクチャ(エンコーダーとデコーダーの両部分を有していた)のデコーダー部分のみを使用しています。デコーダーは、以前に見たトークンに基づいて、1トークンずつテキストを生成する役割を担います。これは自己回帰的な方法で動作し、つまり、文脈としてすべての前の単語を使用して次の単語を予測します。
各デコーダーブロックには以下が含まれます:
- マスキング付きマルチヘッド自己注意層
- フィードフォワードニューラルネットワーク(FFN)
- 残差接続と層正規化
入力表現
モデルがテキストを処理する前に、数値形式に変換します:
- トークン化:単語または部分単語を、バイトペアエンコーディング(BPE)などの手法でより小さな単位(トークン)に分割します。
- 埋め込み層: 各トークンを高次元ベクトル(埋め込み)にマッピングします。
- 位置エンコーディング: トランスフォーマーはRNNのようにデータを順次処理しないため、GPTはトークンに位置埋め込みを追加し、シーケンス内の順序を符号化します。
マスク付きマルチヘッド自己注意
これはGPTの中核です。注意機構により、テキスト生成時に文脈の関連部分に焦点を当てられます。GPTは因果的(マスク付き)注意を使用し、左から右への生成ルールを維持するため、先読みしないことを保証します。
フィードフォワードニューラルネットワーク(FFN)
各デコーダブロックには位置ごとのフィードフォワードネットワークがあり、データを非線形に変換します。これにより各位置で独立した変換を適用し、モデルの表現力を強化します。
残差接続と正規化
各サブレイヤー(アテンションとFFN)には残差接続とそれに続くレイヤ正規化が含まれます。これにより学習が安定し、非常に深いネットワーク全体での勾配の流れが改善されます。
モデルの深さと規模
GPTの各新世代では以下が増加:
- 層数(トランスフォーマーブロック)
- 隠れサイズ(埋め込み次元)
- アテンションヘッド数
- 訓練データの規模と多様性
| モデル | レイヤー数 | パラメータ数 | コンテキストウィンドウ | 発表年 |
| GPT-1 | 12 | 1億1,700万 | 512トークン | 2018年 |
| GPT-2 | 48 | 15億 | 1,024トークン | 2019年 |
| GPT-3 | 96 | 1,750億 | 2,048トークン | 2020年 |
| GPT-4 | 約120以上 | 推定1兆以上 | 8K〜128Kトークン | 2023年 |
| GPT-5 | 高度なマルチモーダルモデル | 不明(推定で数兆規模) | 256K以上のトークン | 2025年 |
ファインチューニングと強化学習
後続モデル(GPT-4やGPT-5など)では以下を活用:
- 教師ありファインチューニング(SFT):高品質な人間によるアノテーション付きテキストでの訓練。
- RLHF(人間からのフィードバックに基づく強化学習):モデルの応答を人間の選好に整合させる。
- ツール/エージェント統合: GPT-5はAPIを呼び出し、ウェブを閲覧し、自律的にアクションを実行できる。
GPTモデルの進化
GPT-4の反復から現在のGPT-5に至る道のりは、OpenAIのモデル開発における重要なマイルストーンである。このパラダイムは、会話アシスタントから推論とマルチモーダルフレームワークへと移行した。
GPT-4からGPT-4.5へ:洗練と拡張
GPT-4シリーズは高性能大規模言語モデルの基盤を築いた。GPT-4.1、 GPT-4.5、 GPT-4oなどのバージョンでは以下の主要な強化が導入された:
- マルチモーダリティ: 単一モデル内でのテキスト・画像・音声処理の統合。
- 速度と効率性 : mini バージョン(GPT-4.1-mini や o4-mini など)は、強力な推論能力を維持しながら、より高速な推論のために最適化されました。
- より高い文脈理解力: o4-mini-high などのモデルは、より長いコンテキストウィンドウを処理し、複雑なクエリに対してより首尾一貫した応答を提供することができました。
これらのモデルは、軽量なアシスタントと深い分析的推論システムとの間のギャップを埋めるものでした。
推論モデル
OpenAIによるo3(および後継のo4-miniバリエーション)の導入は転換点となった。これらのモデルは明示的な推論行動を初めて示したものである。
単に次のトークンを予測するのではなく、多段階の思考プロセスを実行するよう訓練され、内部の「推論連鎖」をシミュレートした。
この革新により新たなカテゴリーが誕生した:思考モデル。
これらは構造化された論理的出力を提供し、問題解決、コーディング課題、段階的分析をはるかに高い精度で処理できた。
レガシーモデル
GPT-4o、GPT-4.1、o3、o4-miniを含むレガシーモデルは、今日の先進システムの基盤を築いたChatGPTの初期世代を代表する。最新バージョンではないものの、マルチモーダリティ、拡張コンテキストウィンドウ、初期推論能力の導入において重要な役割を果たし、これらは統合されたGPT-5フレームワークへと進化しました。
- GPT-4oは2024年5月に導入され、OpenAI初の完全マルチモーダルモデルとして、テキスト・画像・音声入力をリアルタイムで理解可能でした。最大128Kトークンという拡張されたコンテキストウィンドウを備え、ChatGPTとOpenAI APIの両方を通じて利用可能となり、GPT-5に置き換えられるまで最も汎用性の高いGPT-4バリエーションとなりました。
- GPT-4.1は2024年末にリリースされ、128Kトークンのコンテキスト制限を維持しつつ、推論精度、信頼性、ツール統合性を強化しました。数か月間、ChatGPT PlusおよびAPIユーザーのデフォルトモデルとして機能し、GPT-4.5およびGPT-5のリリースに伴い段階的に廃止されるまで、企業レベルの一貫性を提供しました。
- o3は2025年初頭にリリースされ、構造化された段階的な分析と論理的問題解決を実行できるOpenAIの推論モデルラインのデビューを飾りました。200Kトークンのコンテキストウィンドウをサポートし、推論タスクを実験する開発者向けにOpenAI API経由でのみ利用可能でした。
- o4-miniはo3の直後に導入され、迅速な応答と低遅延に最適化された高速軽量推論モデルを提供しました。128Kトークンのコンテキストウィンドウをサポートし、ChatGPTとAPIエンドポイントの両方からアクセス可能でした。
GPT-5:統一されたマルチモーダル知能フレームワーク
この基盤をさらに発展させ、GPT-5はGPT-4シリーズとThinkingモデルの両方の強みを単一の統合フレームワークに統合しました。
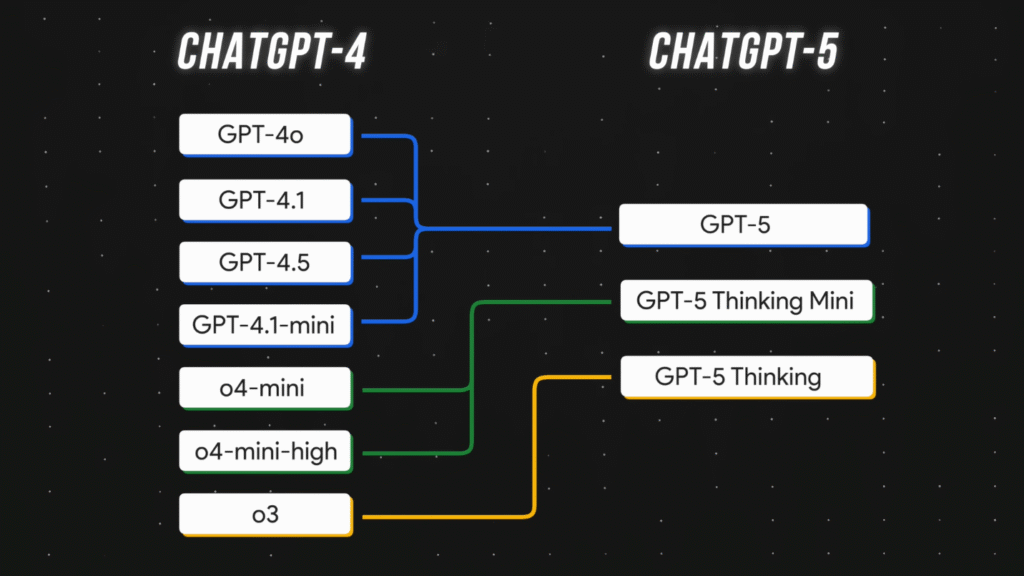
図に示す通り:
- GPT-4o、GPT-4.1、GPT-4.5:これらは深層マルチモーダル理解(テキスト、画像、音声など)を提供するフラッグシップモデルであるGPT-5へと進化しました。
- o4-mini および o4-mini-high:高速かつ構造化された問題解決を目的とした軽量推論モデル GPT-5 Thinking Mini に進化。
- o3:多段階認知計画・分析・長文脈理解が可能な最先端の熟慮型推論システム GPT-5 Thinking に進化。
GPT-5とその派生モデル
以下に、様々なGPT-5モデルの詳細な概要をご確認いただけます。
| モデル | 特徴 | 用途 |
| GPT-5 | マルチモーダル入力対応、256K以上のトークン文脈、統合推論システム | 高度な生成、長文処理、マルチメディア解析 |
| GPT-5 Thinking | ステップごとの思考処理、問題解決と計画タスク最適化 | 分析、推論、科学・エンジニアリングタスク |
| GPT-5 Thinking Mini | 軽量で高速、効率的な論理推論に特化 | 日常的な自動化、B2B業務、教育ツール |
GPT-5の活用事例
GPT-5は、高度な研究やデータ分析から創造的なコンテンツ生成、自律的なタスク実行に至るまで、幅広い実世界のアプリケーションを支えています。その推論能力とマルチモーダル機能は、深い理解と正確な意思決定が不可欠な教育、金融、医療、ソフトウェア開発などの業界に最適です。
リスクとリターンのバランスを取るための投資オプション評価
GPT-5は、多様なポートフォリオにおけるリスクとリターンのバランスを目指す投資家にとって強力な分析アシスタントとして機能します。高度な推論とデータ分析能力を活用し、財務諸表、市場動向、過去のパフォーマンスデータを処理して最適な投資組み合わせを特定します。GPT-5は様々なリスクシナリオをシミュレートし、資産クラスを比較し、投資家のリスク許容度や財務目標に沿った洞察を生成できるため、現代のポートフォリオ管理における貴重な意思決定支援ツールとなります。
例として、GPT-5に「現金資金を低コストのインデックスファンドとマネーマーケット口座のどちらに置くべきか」のメリット・デメリットを尋ねました。このプロンプトには「よく考えてください」というニュアンスを加えるため、末尾に“think hard about this”を追加しました。46秒間思考した後、プロンプトに対して簡潔でコンサルタント風の分析結果を提供しました。
このプロンプトに含まれる誘導フレーズは、より深い思考を引き起こしました。特に、ハイステークスなタスクでは、二次的な影響を見逃すと、ユーザーのプロンプト応答に深刻な悪影響を及ぼす可能性があります。
LinkedInにおけるネットワーキングとキャリア成長
GPT-5は、LinkedInでネットワークを拡大しキャリア成長を促進したいプロフェッショナルにとって、かけがえのない味方となり得ます。プロフィールを分析し、業界や目標に合わせた最適化された見出し、インパクトのある要約、パーソナライズされたコネクションメッセージを提案します。トレンドトピックやエンゲージメントパターンのリアルタイムインサイトを活用することで、GPT-5は有意義な交流を誘発する本物の投稿作成も支援します。さらに、ネットワーキング戦略のシミュレーション、参加すべきグループやコミュニティの推薦、真のプロフェッショナル関係を構築する思慮深い返信の草案作成まで可能にし、LinkedInを持続的なキャリア発展のための強力なプラットフォームへと変えます。
具体例として、GPT-5に「キャリア成長におけるネットワーキングの重要性」をテーマに、250語以内でLinkedIn投稿を作成させました。2~3の実践的アドバイスを含め、企業用語を避け、強力なストーリーテリングと独創性、思考を促す行動喚起(CTA)を盛り込み、品質向上のため最大5回まで推敲しました。49秒で生成された投稿は、強力なストーリーテリングと独創性を備え、末尾にCTAが配置されていました。
自己批判手法を採用し、回答を反復的に改善するため最後に品質評価基準表を組み込んだ。GPT-5は最大5回の内部改善サイクルを実行し、提示された全基準を満たす最良のバージョンを生成した。

GPTモデルの課題と考慮点
生成型事前学習トランスフォーマー(GPT)モデルは、自然言語理解、自動コンテンツ生成、大規模対話システムの実現を通じて、人間と人工知能の関わり方を変革した。しかし、これらのモデルには精度、倫理的な利用、長期的な社会的影響に影響を与える様々な課題と考慮点が存在する。GPTベースのシステムを責任を持って展開しようとする研究者、開発者、政策立案者にとって、これらの限界を理解することは極めて重要である。
事実誤認と幻覚現象
GPTモデルの最も議論される限界の一つは、「幻覚」を生成する傾向です。これは確信を持って述べられるものの、事実誤認や虚偽の情報です。これはモデルが真の理解ではなく統計的パターンに基づいて応答を生成するため発生します。人間からのフィードバックを用いた強化学習(RLHF)や検索強化生成(RAG)などの取り組みにもかかわらず、幻覚は特に専門分野やリソース不足の領域で持続的な問題となっています。
バイアスと公平性の懸念
GPTモデルは、社会的格差、固定観念、文化的偏りを反映したトレーニングデータに内在するバイアスを継承する。こうしたバイアスは、性別・人種・政治的な言語表現として現れ、差別的な出力につながる。公平性を確保するには継続的なデータ管理、バイアス検出、アルゴリズム監査が必要だが、バイアスは文脈依存性が高く言語そのものに深く根ざしているため、完全な中立性は依然として困難である。
倫理的・社会的影響
GPTモデルの普及に伴い、悪用に関する倫理的懸念が高まっている。これにはディープフェイク生成、偽情報拡散、偽レビュー作成、さらには個人なりすましが含まれる。さらに、コンテンツ生成の自動化はクリエイティブ産業や労働市場を混乱させる可能性がある。イノベーションと説明責任のバランスを取るには、明確な倫理ガイドライン、データソースの透明性、堅牢なコンテンツモデレーションメカニズムが求められる。
データプライバシーとセキュリティ
GPTモデルの訓練に用いられる膨大なデータセットには、公的・準公的ソースから収集された情報が含まれることが多い。これによりデータプライバシーや個人・機密情報の意図せぬ流出が懸念される。さらにプロンプト注入やデータ抽出攻撃がシステムの脆弱性を悪用する可能性がある。開発者は差分プライバシー、コンテンツフィルタリング、きめ細かいアクセス制御などの安全対策を実施し、悪用を防止しなければならない。
解釈可能性と透明性
優れた性能にもかかわらず、GPTモデルは「ブラックボックス」として機能する。内部の意思決定プロセスは解釈が困難であり、特定の出力が生成される理由を理解するのが難しい。この説明可能性の欠如は、医療、法律、金融などのハイリスク領域において、信頼性と説明責任を阻害する。説明可能なAI(XAI)に関する継続的な研究は、これらのシステムをより透明で理解しやすいものにすることを目指している。
計算コストと環境への影響
大規模GPTモデルのトレーニングには膨大な計算資源とエネルギー消費を要する。これは環境への負荷が大きく、小規模組織や発展途上地域でのアクセスを制限する。効率的なアーキテクチャ、量子化、モデル蒸留への取り組みは、性能を維持しつつこれらの持続可能性への懸念に対処しようとしている。
規制と法的考慮事項
GPT技術の急速な普及は、包括的な法的枠組みの整備を追い越している。著作権侵害、データ所有権、AIの責任問題など多くの法域で未解決の課題が残る。政府や国際機関はイノベーションと利用者保護のバランスを取る政策策定に取り組んでいるが、世界的な合意形成は進行中である。
過度の依存と人的監視
GPTシステムがワークフローに統合されるにつれ、十分な人的監視なしにAI出力に過度に依存するリスクが生じます。特に権威ある口調と流暢さで生成された応答を、ユーザーが表面的に受け入れる可能性があります。批判的評価の促進、透明性ラベル、ヒューマン・イン・ザ・ループ設計は、この課題の軽減に寄与します。
よくある質問
ChatGPTの学習にはどのような公開情報が使用されていますか?
ChatGPTはインターネット上で自由にアクセス可能な公開情報で訓練されています。有料サイトやダークウェブのデータは除外されています。ヘイトスピーチ、成人向けコンテンツ、個人データ、スパムなどの望ましくないコンテンツを除去するフィルターを適用した後、残りのデータを用いて訓練が行われます。
ChatGPTの学習にどのような公開情報が使用されていますか?
OpenAIはトレーニングにオンラインで自由にアクセス可能なコンテンツのみを使用し、有料コンテンツやダークウェブのソースは除外しています。ヘイトスピーチ、成人向けコンテンツ、個人データ、スパムはフィルターで除去され、残りのデータがモデルのトレーニングに使用されます。
GPT-5 Proとは?
GPT-5 ProはOpenAIの最先端AIモデルであり、コーディング、研究、問題解決などの複雑なタスクにおいて、強化された推論能力、精度、パフォーマンスを提供します。ChatGPT ProおよびBusinessプランを通じて利用可能で、無制限のアクセスと高度な機能を提供します。無料またはPlusプランでは利用不可のため、アクセスには有料サブスクリプションが必要です。


